全球算力巅峰 Atlas 900背后的网络技术揭秘
本站点使用Cookies,继续浏览表示您同意我们使用Cookies。Cookies和隐私政策>![]()

华为在 2019 年全联接大会上发布的 AI 训练集群 Atlas 900,代表了当今全球的算力巅峰。这么大的算力如果运行 ResNet-50@ImageNet 只需59.8 秒就可完成训练,排名全球第一。那么这个速度到底有多快?它的关键技术难点在哪儿?为什么华为可以做到?本文将详细解读这些疑问背后的关键技术支撑。
前面提到 ImageNet,我们先来看看 ImageNet 是个什么?ImageNet 刚开始是一个计算机视觉系统识别项目,是目前世界上图像识别最大的数据库,大约包含上千万张标记的样本图片,为众多的图像识别 AI 算法提供样本数据。从 2010 年开始,开始举办 ImageNet 大规模视觉识别挑战赛。ImageNet 现在成为一个业界权威的 AI 竞技场,短短 7 年内,AI 优胜者的识别率就从71.8% 提升到 97.3%,超过了人类,极大促进了 AI 技术的飞速发展。
目前 ImageNet 已经不仅仅是一个 AI 算法竞技场,也成为众多 AI 厂商 AI 算力的竞技场,完成一次 ImageNet 训练的时间已经成为业界AI算力金标准。我们看看过去几年业界相关的新闻:
• 2017年9月,24分钟完成 ImageNet 训练,刷新世界纪录(UC Berkeley);
• 2017年11月,11分钟训练完 ImageNet,DNN 训练再破纪录(UC Berkeley);
• 2018年8月,世界纪录!4分钟训练完 ImageNet!(腾讯)
可以看出,业界毫不掩饰对于训练完成时间每缩短几分钟后的欣喜感。不难理解的是这样一个完成一次训练任务大约需要百亿亿次的浮点计算,即便是用全球性能最高的超级计算机,也需要较长时间,而华为 Atlas900 训练集群一举将该训练时间缩短到秒级,取得里程碑式突破,获得 GSMA GLOMO 未来技术大奖实至名归。
如何提升 AI 训练的算力,一个很容易想到的方法就是采用更高性能的处理器,诚然如此,AI 处理器的性能是整个集群性能的基础,近几年来 AI 处理器的处理性能井喷式发展。但是一个集群往往涉及到成千上万的 AI 处理器参与计算,如何有效的协同才是当前业界面临最大的难题。
• 单台 AI 服务器性能看处理器
Atlas 900 AI 训练集群采用业界单芯片算力最强的昇腾处理器,整体浮点计算峰值能力有望接近到 P 级。但是即便如此,远远不够完成一个 AI 训练(比如 ImageNet训练)所要求的百亿亿次浮点计算要求,需要更多的 AI 服务器组成一个集群协同才能完成。那么是不是AI训练集群的规模越大,算力就越强呢?非常遗憾,答案是否定的,这也成为 AI 训练集群性能提升真正的难点值所在。
• AI 训练集群性能瓶颈在网络
我们知道,2 台服务器组成的 AI 集群,整体性能理论上应该是单台的 2 倍,但由于协同的开销,只能达到 1.x 倍。根据业界经验,当 AI 集群规模达到 32 个节点的时候,最高只能达到理论性能的一半。如果再增加服务器节点不仅不能提升整体集群的性能,甚至有可能会下降。所有的 AI 训练集群都存在它的性能天花板。
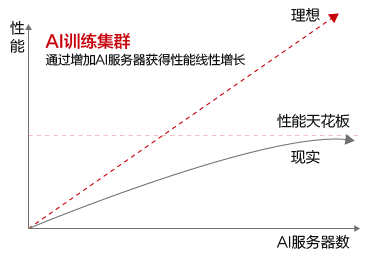
为什么会发生这样的现象?详细分析原因,会发现 AI 训练集群在完成一次训练的时候会涉及到多个服务器之间频繁的大量的参数同步,一旦服务器规模变大,网络拥塞就会很严重,产生网络丢包。 实测数据得知即便只有 1‰的网络丢包就可能造成接近 50% 的网络吞吐下降,而丢包率会随着服务器节点数的增加而增加,如果丢包率达到 2% 的时候,整个网络将陷入瘫痪状态。不难看出,网络丢包成为 AI 集群性能提升的瓶颈,也成为 AI 集群性能提升的天花板。
作为全球最快的 AI 训练集群 Atlas 900,实现了数千颗昇腾处理器组成的上百台服务器节点互联构成。Atlas 900 如何突破性能天花板,确保这几百个服务节点之间的高效无损互联,不造成算力损失,构建一个 0 丢包的网络成为需要解决的首要问题?

• 七年磨一剑,瞄准智能无损
早在 2012 年,华为为了应对未来数据洪水挑战,投入数十个科学家开始新一代无损网络的研究,致力于构建 0 丢包、低时延的以太网。七年如一日,经过多方向多路径的艰难探索,通过 AI 技术实现网络拥塞调度和网络自优化的 iLossless 算法方案,取得了突破性的进展。
iLossless 算法为以太网的流量调度提供了智能预测能力,根据当前流量状态可以精准预测下一刻的拥塞状态,提前做好预留和准备。就好像我们看到警车开道就可以提前预测可能戒严的拥塞路段,根据机场航班起飞和降落的密集度可以预测机场高速的拥塞程度,提前做好调度,从而提高交通的通行率。
不过 iLossLess 算法作为AI算法,它的真正商用还必须依赖大量样本数据的训练,华为在过去的几年来与数百个客户联合创新,基于客户的现网运行场景和独创的随机样本生成技术积累了数千万的有效样本数据,训练的效果达到了理想目标,在任何场景下都实现了 100% 吞吐下的 0丢包。
这一创新成果终结了以太网四十多年来一旦拥塞容易丢包的历史。目前在华为主导下,IEEE 已经成立了 Nendica(IEEE802 “Network Enhancements for the Next Decade” IndustryConnections Activity)工作组,成为以太网技术标准发展的新方向。
• 业界唯一0丢包的以太网,助力Atlas冲击全球算力巅峰
2019年初,华为发布了业界首款面向AI时代的CloudEngine 数据中心交换机,率先将 AI 芯片内嵌交换机中,独创iLossless智能无损交换算法得到了最佳的运行平台,目前算法、算据和算力三大 AI 关键要素全部具备,新一代 CloudEngine 交换机完成了多年核心技术研究成果到商业落地的突破。
采用CloudEngine系列交换机组成智能无损的全网 0 丢包以太网络。Atlas900 就是这样的0丢包以太网连接而成, 0丢包的以太网为 Atlas 集群内的每一个AI服务器提供 8*100GE的接入能力,从而实现百TB全互联无阻塞 0 丢包专属参数同步网络。基于全球最高密度400G的 CloudEngine16800 构筑的智能无损DCN,不仅满足Atlas当前集群的0丢包诉求,更支持大规模400GE组网演进,为未来的 Scale-out 性能线性扩展提供了保障,确保持续的性能巅峰。
华为智能无损DCN真正实现 0 丢包,100%释放 AI 算力,助力Atlas900冲击并持续保持全球算力巅峰。
华为智能无损DCN不仅仅是面向AI训练集群的高性能网络,更是代表面向云和 AI 数据中心的下一代网络新架构。它在全闪存分布式存储、分布式数据库、以计算为核心的 HPC,以及大数据场景,都有极强的性能优势。第三方权威机构 Tolly 测试结果表明,0 丢包的智能无损 DCN 提升了 30% 的业务性能,完全可以和专网相媲美。
构建一张融合的数据中心网络一直是网络运营者的梦想。华为智能无损 DCN 的发布,使得数据中心三网融合成为可能。目前在华为云、招行分行云、百度、UCloud 等全球 47 个数据中心得到商用部署,实现计算网,存储网和业务网的归一化。据测算,统一融合的数据中心网络部署后可带来 TCO 降低 53%。
智能无损数据中心网络,正在成为智能时代三网融合 DCN架构的基石!




